![]() USU
››
ව්යාපාර ස්වයංක්රීයකරණය සඳහා වැඩසටහන්
››
සායනය සඳහා වැඩසටහන
››
වෛද්ය වැඩසටහන සඳහා උපදෙස්
››
USU
››
ව්යාපාර ස්වයංක්රීයකරණය සඳහා වැඩසටහන්
››
සායනය සඳහා වැඩසටහන
››
වෛද්ය වැඩසටහන සඳහා උපදෙස්
››
![]() වගුවක වචන සෙවීම ක්රියා කරන ආකාරය ඉගෙන ගැනීමට පෙර, පළමුව වර්ග කිරීමේ ක්රම දෙස බලන්න.
වගුවක වචන සෙවීම ක්රියා කරන ආකාරය ඉගෙන ගැනීමට පෙර, පළමුව වර්ග කිරීමේ ක්රම දෙස බලන්න.

දැන් අපි වගුවේ අපේක්ෂිත පේළිය ඉක්මනින් සොයා ගන්නේ කෙසේදැයි ඉගෙන ගැනීමට පටන් ගනිමු. විශාල දත්ත ප්රමාණයක් සමඟ වැඩ කරන විට, කාර්යය නිරන්තරයෙන් පැන නගී: වගුවේ ඇති වචන සොයා ගන්න. එවැනි සෙවුමක් සඳහා, ඔබ සොයන පාඨය ඇතුළු කරන විශේෂ ආදාන ක්ෂේත්ර කිසිවක් අපට අවශ්ය නොවනු ඇත. සෑම දෙයක්ම වඩා පහසු සහ පහසු වේ!
උදාහරණයක් ලෙස, අපි සේවක නාමාවලියෙහි නිවැරදි පුද්ගලයා සොයමු "නම විසින්" . එමනිසා, අපි මුලින්ම දත්ත ' FULL NAME ' තීරුවෙන් වර්ග කර වගුවේ පළමු පේළියේ සිටගෙන සිටිමු.

දැන් අපි යතුරුපුවරුවේ අපි සොයන පුද්ගලයාගේ නම ටයිප් කිරීමට පටන් ගනිමු. ඇතුල් කරන්න ' සහ ', ඉන්පසු ' to '. අපි ' සහ ' කුඩා අකුරින් ඇතුළත් කළත්, වගුවේ ' ඉවානෝවා ඔල්ගා ' විශාල අකුරකින් ලියා ඇතත්, වැඩසටහන වහාම අවධානය යොමු කරයි.
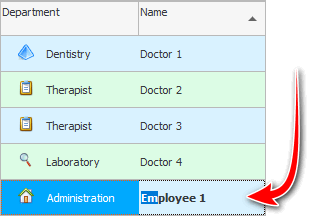
මෙය ' ඉක්මන් පළමු අකුරු සෙවීම ' හෝ ' සන්දර්භය සෙවීම ' ලෙස හැඳින්වේ. මේසය තුළ සේවකයින් දහස් ගණනක් ඇතුළත් කළත්, ඔබ අක්ෂර ඇතුළත් කරන විට වැඩසටහන ක්ෂණිකව නිවැරදි පුද්ගලයා සොයා ගනී.

වගුවේ සමාන අගයන් තිබේ නම්, උදාහරණයක් ලෙස, " ඉවානෝවා " සහ " ඉවානිකොව් ", " අයිවන් " යන පළමු අකුරු හතර ඇතුළත් කිරීමෙන් පසු, අවධානය යොමු කරනු ලබන්නේ සමීපව සිටින සේවකයා වෙත ය. පස්වන අක්ෂරය, වැඩසටහන දැනටමත් අවශ්ය පුද්ගලයා පෙන්වනු ඇත . අපි පස්වන අක්ෂරය ලෙස ' n ' ලියන්නේ නම්, වැඩසටහන ' Ivannikov ' පෙන්වයි. එක් එක් අක්ෂරය ඇතුළත් කිරීමේදී අනුපිළිවෙලින් සෙවුම් පෙළට ගැලපෙන පරිදි පළමු අක්ෂරවල සෙවීම වගුවේ ඇති අගයන් සංසන්දනය කරන බව පෙනේ.

ඔබ එක් භාෂාවකින් අකුරු එබීමට උත්සාහ කරන්නේ නම් සෙවුම ක්රියා නොකරනු ඇති අතර පහළ දකුණු කෙළවරේ වින්ඩෝස් මෙහෙයුම් පද්ධතියේ සම්පූර්ණයෙන්ම වෙනස් භාෂාවක් ක්රියාත්මක වේ.


![]() වාක්ය ඛණ්ඩයක ආරම්භයේ දී පමණක් නොව මැදින් ද ඇති විය හැකි ඔබ සොයන අගයෙන් කොටසක් පමණක් ඔබ දන්නේ නම්, වචනයක කොටසකින් සොයන්නේ කෙසේදැයි මෙතැනින් බලන්න .
වාක්ය ඛණ්ඩයක ආරම්භයේ දී පමණක් නොව මැදින් ද ඇති විය හැකි ඔබ සොයන අගයෙන් කොටසක් පමණක් ඔබ දන්නේ නම්, වචනයක කොටසකින් සොයන්නේ කෙසේදැයි මෙතැනින් බලන්න .

![]() ඔබට මුළු වගුවම සෙවිය හැකිය.
ඔබට මුළු වගුවම සෙවිය හැකිය.
වෙනත් ප්රයෝජනවත් මාතෘකා සඳහා පහත බලන්න:
![]()
විශ්ව ගිණුම්කරණ පද්ධතිය
2010 - 2024
 අන්තර් ක්රියාකාරී පුහුණුව සමඟ වැඩසටහන බාගත කරන්න
අන්තර් ක්රියාකාරී පුහුණුව සමඟ වැඩසටහන බාගත කරන්න