![]() USU
››
Programmid ettevõtte automatiseerimiseks
››
Kliiniku programm
››
Meditsiiniprogrammi juhised
››
USU
››
Programmid ettevõtte automatiseerimiseks
››
Kliiniku programm
››
Meditsiiniprogrammi juhised
››
![]() Enne kui saate teada, kuidas tabelist sõnade otsimine töötab, vaadake esmalt sortimismeetodeid .
Enne kui saate teada, kuidas tabelist sõnade otsimine töötab, vaadake esmalt sortimismeetodeid .

Nüüd hakkame õppima, kuidas kiiresti tabelist soovitud rida leida. Suurte andmemahtudega töötades tekib pidevalt ülesanne: leida tabelist sõnad. Selliseks otsinguks ei vaja me spetsiaalseid sisestusvälju , kuhu sisestaksite otsitava teksti. Kõik on palju lihtsam ja mugavam!
Näiteks otsime õiget inimest töötajate kataloogist "nimepidi" . Seetõttu sorteerime andmed esmalt veeru " TÄISNIMI " järgi ja seisame tabeli esimesel real.

Ja nüüd hakkame lihtsalt otsitava inimese nime klaviatuuril tippima. Sisestage " ja ", seejärel " kuni ". Kuigi me sisestame ' ja ' väiketähtedega ning tabelis on ' Ivanova Olga ' kirjutatud suure algustähega, liigutab programm kohe fookuse sellele.
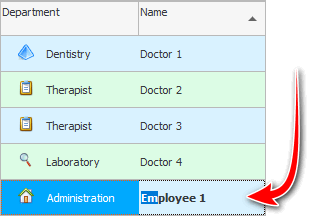
Seda nimetatakse kiireks esimese tähe otsinguks või kontekstiotsinguks . Isegi kui tabelisse on sisestatud tuhandeid töötajaid, leiab programm tähemärkide sisestamisel kohe õige inimese.

Kui tabelis on sarnased väärtused, näiteks ' Ivanova ' ja ' Ivannikov ', siis pärast nelja esimese tähe sisestamist ' Ivan ' keskendutakse esmalt töötajale, kes asub lähemal ja sisestamisel viies märk, näitab programm juba vajalikku isikut . Kui kirjutame viienda märgina " n ", kuvab programm " Ivannikov ". Selgub, et esimeste märkide otsing võrdleb iga märgi sisestamisel tabelis olevaid väärtusi, et need sobiksid järjestikku otsingutekstiga.

Otsing ei pruugi töötada, kui proovite vajutada tähti ühes keeles ja Windowsi operatsioonisüsteemis on all paremas nurgas aktiivne hoopis teine keel.


![]() Kui teate ainult osa otsitavast väärtusest, mis võib esineda mitte ainult fraasi alguses, vaid ka fraasi keskel, siis vaadake siit, kuidas otsida sõna osa järgi .
Kui teate ainult osa otsitavast väärtusest, mis võib esineda mitte ainult fraasi alguses, vaid ka fraasi keskel, siis vaadake siit, kuidas otsida sõna osa järgi .

![]() Võite otsida ka kogu tabelit .
Võite otsida ka kogu tabelit .
Teisi kasulikke teemasid vaadake allpool:
![]()
Universaalne raamatupidamissüsteem
2010 - 2024
 Laadige programm alla interaktiivse koolitusega
Laadige programm alla interaktiivse koolitusega