![]() USU
››
व्यापार स्वचालन को लागी कार्यक्रम
››
क्लिनिकको लागि कार्यक्रम
››
चिकित्सा कार्यक्रम को लागी निर्देशन
››
USU
››
व्यापार स्वचालन को लागी कार्यक्रम
››
क्लिनिकको लागि कार्यक्रम
››
चिकित्सा कार्यक्रम को लागी निर्देशन
››
![]() यी सुविधाहरू मानक र व्यावसायिक कार्यक्रम कन्फिगरेसनहरूमा मात्र उपलब्ध छन्।
यी सुविधाहरू मानक र व्यावसायिक कार्यक्रम कन्फिगरेसनहरूमा मात्र उपलब्ध छन्।

जब हामीले राख्न सिक्यौं ![]() हल्का फिल्टरहरू , जहाँ हामी कुनै पनि फिल्डको वांछित मानहरूमा मात्र टिक गर्छौं। यो कठिन परिस्थितिहरू काम गर्ने समय हो ताकि, मोड्युलको उदाहरण प्रयोग गरेर "बिरामीहरू" जटिल डेटा फिल्टरिङ सेटअपले कसरी काम गर्छ हेर्नुहोस्।
हल्का फिल्टरहरू , जहाँ हामी कुनै पनि फिल्डको वांछित मानहरूमा मात्र टिक गर्छौं। यो कठिन परिस्थितिहरू काम गर्ने समय हो ताकि, मोड्युलको उदाहरण प्रयोग गरेर "बिरामीहरू" जटिल डेटा फिल्टरिङ सेटअपले कसरी काम गर्छ हेर्नुहोस्।
साथ ![]() अघिल्लो उदाहरणमा, हामीसँग पहिले नै फिल्टर विन्डोमा एक अवस्था छ।
अघिल्लो उदाहरणमा, हामीसँग पहिले नै फिल्टर विन्डोमा एक अवस्था छ।
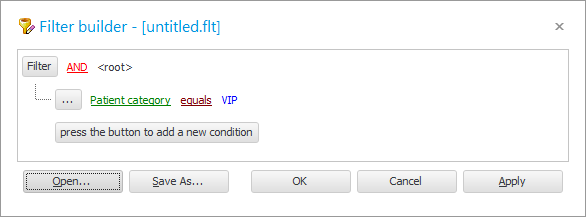
' बिरामी श्रेणी ' फिल्डलाई ' नाम ' फिल्डले प्रतिस्थापन गरौं।
तुलना चिन्हलाई ' समान ' बाट ' समान ' मा परिवर्तन गर्नुहोस्।
मानको रूपमा, ' % van % ' प्रविष्ट गर्नुहोस् ।
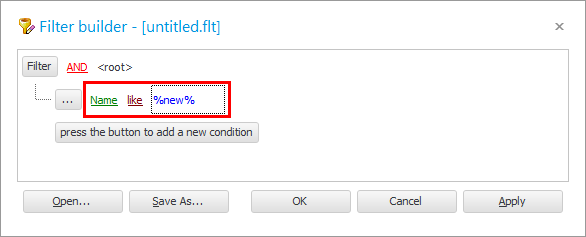
' OK ' बटन थिच्नुहोस् र नतिजा हेर्नुहोस्।
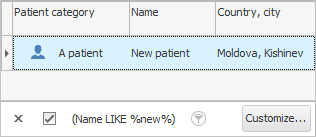
हामीले के गरेका छौं? हामीले लेखेका कुराहरूसँग ओभरल्याप हुने प्रविष्टिहरू खोज्न सिकेका छौं। त्यसकारण हामीलाई तुलना चिन्ह ' जस्तो देखिन्छ ' चाहिन्छ। र ' % van % ' शब्दको बायाँ र दायाँ तर्फ प्रतिशत चिन्हहरूको अर्थ हो कि तिनीहरूलाई फिल्डमा 'कुनै पाठ' द्वारा प्रतिस्थापन गर्न सकिन्छ। "बिरामीको नाम" ।
यस अवस्थामा, हामी सबै कर्मचारीहरू देखाइयो जसको पहिलो वा अन्तिम नाम वा संरक्षकमा 'ivan' शब्द छ। यो 'Ivans', र 'Ivanovs', र 'Ivannikovs', र 'Ivanovichi', आदि हुन सक्छ। डाटाबेसमा बिरामीको ' पूरा नाम ' कसरी लेखिएको छ भन्ने थाहा नभएको अवस्थामा यो मेकानिजम प्रयोग गर्न सजिलो हुन्छ। र जब सबै समान रेकर्डहरू प्रदर्शित हुन्छन्, तपाईं सजिलै आफ्नो आँखाले सही व्यक्ति चयन गर्न सक्नुहुन्छ।
प्रतिशत चिन्ह खोज वाक्यांशको सुरु र अन्त्यमा मात्र होइन, बीचमा पनि प्रयोग गर्न सकिन्छ। त्यसपछि तपाइँ पहिलो नामको अंश र अन्तिम नामको अंश निर्दिष्ट गर्न सक्नुहुन्छ। उदाहरणका लागि, ' नयाँ ग्राहक ' को सट्टा ' %ov%lie% ' लेख्न सम्भव छ। लामो नामको अवस्थामा, यस्तो लुकअप मेकानिजमले टाइपिङ समयलाई धेरै कम गर्छ।

अन्तमा, जब तपाईंले डाटा फिल्टरिङको प्रयोग समाप्त गर्नुभयो, फिल्टरिङ प्यानलको बायाँ छेउमा रहेको 'क्रस' मा क्लिक गरेर फिल्टर रद्द गरौं।
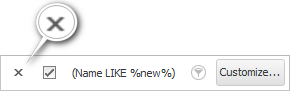

![]() अब धेरै सर्तहरूसँग फिल्टरिङ हेरौं
अब धेरै सर्तहरूसँग फिल्टरिङ हेरौं ![]() समूहबद्ध गर्न सकिन्छ ।
समूहबद्ध गर्न सकिन्छ ।
अन्य उपयोगी विषयहरूको लागि तल हेर्नुहोस्:
![]()
विश्वव्यापी लेखा प्रणाली
2010 - 2024
 अन्तरक्रियात्मक प्रशिक्षण संग कार्यक्रम डाउनलोड गर्नुहोस्
अन्तरक्रियात्मक प्रशिक्षण संग कार्यक्रम डाउनलोड गर्नुहोस्