![]() USU
››
व्यवसाय ऑटोमेशनसाठी कार्यक्रम
››
क्लिनिकसाठी कार्यक्रम
››
वैद्यकीय कार्यक्रमासाठी सूचना
››
USU
››
व्यवसाय ऑटोमेशनसाठी कार्यक्रम
››
क्लिनिकसाठी कार्यक्रम
››
वैद्यकीय कार्यक्रमासाठी सूचना
››
![]() टेबलमधील शब्द शोधणे कसे कार्य करते हे जाणून घेण्यापूर्वी, प्रथम क्रमवारी पद्धती पहा.
टेबलमधील शब्द शोधणे कसे कार्य करते हे जाणून घेण्यापूर्वी, प्रथम क्रमवारी पद्धती पहा.

आता टेबलमधील इच्छित पंक्ती त्वरीत कशी शोधायची ते शिकूया. मोठ्या प्रमाणात डेटासह कार्य करताना, कार्य सतत उद्भवते: टेबलमधील शब्द शोधा. अशा शोधासाठी, आम्हाला कोणत्याही विशेष इनपुट फील्डची आवश्यकता नाही जिथे तुम्ही शोधत असलेला मजकूर प्रविष्ट कराल. सर्व काही खूप सोपे आणि अधिक सोयीस्कर आहे!
उदाहरणार्थ, आम्ही कर्मचारी निर्देशिकेत योग्य व्यक्ती शोधू "नावाने" . म्हणून, आम्ही प्रथम ' FULL NAME ' स्तंभानुसार डेटाची क्रमवारी लावतो आणि टेबलच्या पहिल्या रांगेत उभे राहतो.

आणि आता आपण कीबोर्डवर ज्या व्यक्तीचा शोध घेत आहोत त्याचे नाव टाईप करणे सुरू करतो. ' आणि ' प्रविष्ट करा, नंतर ' ते '. जरी आपण ' आणि ' लोअरकेसमध्ये एंटर केले आणि टेबलमध्ये ' इव्हानोव्हा ओल्गा ' हे कॅपिटल अक्षराने लिहिलेले असले तरी, प्रोग्राम लगेचच त्याकडे लक्ष केंद्रित करतो.
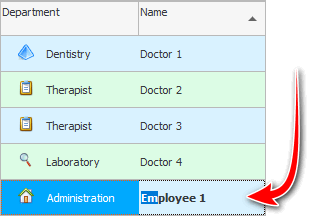
याला ' क्विक फर्स्ट लेटर सर्च ' किंवा ' कॉन्टेक्स्ट सर्च ' म्हणतात. जरी टेबलमध्ये हजारो कर्मचारी प्रविष्ट केले असले तरीही, आपण वर्ण प्रविष्ट केल्यावर प्रोग्राम त्वरित योग्य व्यक्ती शोधेल.

जर टेबलमध्ये समान मूल्ये असतील, उदाहरणार्थ, ' इव्हानोव्हा ' आणि ' इव्हानिकोव्ह ', तर पहिली चार अक्षरे ' इव्हान ' प्रविष्ट केल्यानंतर, लक्ष प्रथम त्या कर्मचाऱ्याकडे जाईल जो जवळ असेल आणि प्रवेश करताना पाचवा वर्ण, कार्यक्रम आधीच आवश्यक व्यक्ती दर्शवेल. जर आपण पाचव्या अक्षराप्रमाणे ' n ' लिहिल्यास, प्रोग्राम ' Ivannikov ' प्रदर्शित करेल. असे दिसून आले की प्रथम वर्णांवरील शोध प्रत्येक वर्ण प्रविष्ट करताना अनुक्रमे शोध मजकूराशी जुळण्यासाठी सारणीतील मूल्यांची तुलना करतो.

जर तुम्ही एका भाषेतील अक्षरे दाबण्याचा प्रयत्न करत असाल आणि खालच्या उजव्या कोपर्यात Windows ऑपरेटिंग सिस्टममध्ये पूर्णपणे भिन्न भाषा सक्रिय असेल तर शोध कार्य करणार नाही.


![]() आपण शोधत असलेल्या मूल्याचा फक्त एक भाग आपल्याला माहित असल्यास, जो केवळ वाक्यांशाच्या सुरुवातीलाच नाही तर मध्यभागी देखील येऊ शकतो, तर शब्दाच्या भागाद्वारे कसे शोधायचे ते येथे पहा.
आपण शोधत असलेल्या मूल्याचा फक्त एक भाग आपल्याला माहित असल्यास, जो केवळ वाक्यांशाच्या सुरुवातीलाच नाही तर मध्यभागी देखील येऊ शकतो, तर शब्दाच्या भागाद्वारे कसे शोधायचे ते येथे पहा.

![]() तुम्ही संपूर्ण टेबल देखील शोधू शकता.
तुम्ही संपूर्ण टेबल देखील शोधू शकता.
इतर उपयुक्त विषयांसाठी खाली पहा:
![]()
युनिव्हर्सल अकाउंटिंग सिस्टम
2010 - 2024
 संवादात्मक प्रशिक्षणासह प्रोग्राम डाउनलोड करा
संवादात्मक प्रशिक्षणासह प्रोग्राम डाउनलोड करा