![]() USU
››
비즈니스 자동화 프로그램
››
진료소 프로그램
››
의료 프로그램 지침
››
USU
››
비즈니스 자동화 프로그램
››
진료소 프로그램
››
의료 프로그램 지침
››
![]() 이러한 기능은 Standard 및 Professional 프로그램 구성에서만 사용할 수 있습니다.
이러한 기능은 Standard 및 Professional 프로그램 구성에서만 사용할 수 있습니다.

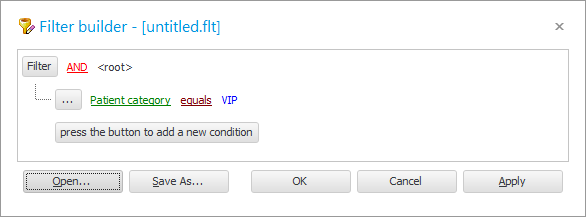
넣는 법을 배웠을 때 ![]() 조명 필터 , 여기서 우리는 단순히 모든 필드의 원하는 값을 선택합니다. 모듈의 예를 사용하여 어려운 조건을 해결해야 할 때입니다. "환자" 복잡한 데이터 필터링 설정이 어떻게 작동하는지 확인하십시오.
조명 필터 , 여기서 우리는 단순히 모든 필드의 원하는 값을 선택합니다. 모듈의 예를 사용하여 어려운 조건을 해결해야 할 때입니다. "환자" 복잡한 데이터 필터링 설정이 어떻게 작동하는지 확인하십시오.
와 함께 ![]() 이전 예에서는 필터 창에 이미 조건이 있습니다.
이전 예에서는 필터 창에 이미 조건이 있습니다.
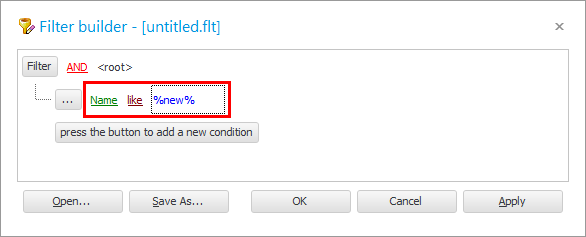
' 환자 범주 ' 필드를 ' 이름 ' 필드로 바꾸겠습니다.
비교 기호를 ' 같음 '에서 ' 유사함 '으로 변경합니다.
값으로 ' %van% '를 입력합니다.
' 확인 ' 버튼을 누르고 결과를 확인합니다.
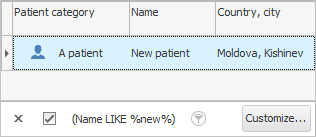
우리는 무엇을 했습니까? 우리는 우리가 쓴 것과 겹치는 항목을 찾는 법을 배웠습니다. 그래서 비교 기호 ' like '가 필요합니다. 그리고 ' %van% '라는 단어의 좌우에 있는 퍼센트 기호는 필드에서 '어떤 텍스트'로 대체될 수 있음을 의미합니다. "환자 이름" .
이 경우 이름이나 성 또는 부칭에 'ivan'이라는 단어가 있는 모든 직원이 표시되었습니다. 'Ivans', 'Ivanovs', 'Ivannikovs', 'Ivanovichi'등이 될 수 있습니다. 이 메커니즘은 환자의 ' 전체 이름 '이 데이터베이스에 어떻게 기록되어 있는지 정확히 모를 때 사용하기 편리합니다. 그리고 비슷한 기록이 모두 표시되면 눈으로 쉽게 올바른 사람을 선택할 수 있습니다.
퍼센트 기호는 검색어의 시작과 끝뿐만 아니라 중간에도 사용할 수 있습니다. 그런 다음 이름의 일부와 성의 일부를 지정할 수 있습니다. 예를 들어 ' New Client ' 대신 ' %ov%lie% '라고 쓸 수 있습니다. 긴 이름의 경우 이러한 조회 메커니즘은 입력 시간을 크게 줄입니다.

마지막으로 데이터 필터링 실험을 마쳤으면 필터링 패널 왼쪽의 '십자'를 클릭하여 필터를 취소해 보겠습니다.

![]() 이제 여러 조건으로 필터링하는 방법을 살펴보겠습니다.
이제 여러 조건으로 필터링하는 방법을 살펴보겠습니다. ![]() 그룹화할 수 있습니다 .
그룹화할 수 있습니다 .
다른 유용한 주제는 아래를 참조하십시오.
![]()
범용 회계 시스템
2010 - 2024
 대화식 교육이 포함된 프로그램 다운로드
대화식 교육이 포함된 프로그램 다운로드