![]() USU
››
პროგრამები ბიზნესის ავტომატიზაციისთვის
››
პროგრამა კლინიკისთვის
››
ინსტრუქციები სამედიცინო პროგრამისთვის
››
USU
››
პროგრამები ბიზნესის ავტომატიზაციისთვის
››
პროგრამა კლინიკისთვის
››
ინსტრუქციები სამედიცინო პროგრამისთვის
››
![]() ეს ფუნქციები ხელმისაწვდომია მხოლოდ სტანდარტული და პროფესიული პროგრამის კონფიგურაციებში.
ეს ფუნქციები ხელმისაწვდომია მხოლოდ სტანდარტული და პროფესიული პროგრამის კონფიგურაციებში.

როცა დაყენება ვისწავლეთ ![]() სინათლის ფილტრები , სადაც უბრალოდ ვნიშნავთ ნებისმიერი ველის სასურველ მნიშვნელობებს. დროა შეიმუშაოს რთული პირობები ისე, რომ მოდულის მაგალითის გამოყენებით "პაციენტები" ნახეთ, როგორ მუშაობს მონაცემთა ფილტრაციის რთული დაყენება.
სინათლის ფილტრები , სადაც უბრალოდ ვნიშნავთ ნებისმიერი ველის სასურველ მნიშვნელობებს. დროა შეიმუშაოს რთული პირობები ისე, რომ მოდულის მაგალითის გამოყენებით "პაციენტები" ნახეთ, როგორ მუშაობს მონაცემთა ფილტრაციის რთული დაყენება.
თან ![]() წინა მაგალითში ჩვენ უკვე გვაქვს მდგომარეობა ფილტრის ფანჯარაში.
წინა მაგალითში ჩვენ უკვე გვაქვს მდგომარეობა ფილტრის ფანჯარაში.
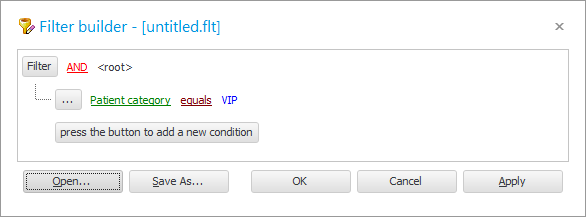
მოდით შევცვალოთ ველი " პაციენტის კატეგორია " ველით " სახელი ".
შეცვალეთ შედარების ნიშანი " ტოლიდან " " მსგავსად ".
როგორც მნიშვნელობა, შეიყვანეთ ' %van% '.
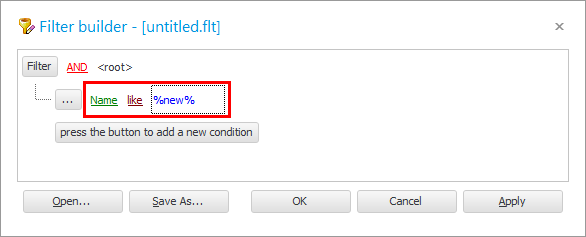
დააჭირეთ ღილაკს " OK " და შეხედეთ შედეგს.
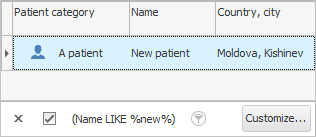
რა გავაკეთეთ? ჩვენ ვისწავლეთ ისეთი ჩანაწერების მოძიება, რომლებიც ემთხვევა იმას, რაც დავწერეთ. ამიტომ ჩვენ გვჭირდება შედარების ნიშანი " ისე ჰგავს ". და პროცენტული ნიშნები მარცხნივ და მარჯვნივ სიტყვა " %van% " ნიშნავს, რომ ისინი შეიძლება შეიცვალოს ველში "ნებისმიერი ტექსტით". "პაციენტის სახელი" .
ამ შემთხვევაში ჩვენ გვაჩვენეს ყველა თანამშრომელი, ვისაც სახელი ან გვარი ან პატრონიმი აქვს სიტყვა „ივანი“. ეს შეიძლება იყოს "ივანები", "ივანოვები", "ივანიკოვები" და "ივანოვიჩი" და ა.შ. ეს მექანიზმი მოსახერხებელია გამოსაყენებლად, როცა ზუსტად არ იცი, როგორ იწერება პაციენტის „ სრული სახელი “ მონაცემთა ბაზაში. და როდესაც ყველა მსგავსი ჩანაწერი გამოჩნდება, თქვენ შეგიძლიათ მარტივად აირჩიოთ სწორი ადამიანი თვალებით.
პროცენტის ნიშანი შეიძლება გამოყენებულ იქნას არა მხოლოდ საძიებო ფრაზის დასაწყისში და ბოლოს, არამედ შუაშიც. შემდეგ შეგიძლიათ მიუთითოთ სახელის ნაწილი და გვარის ნაწილი. მაგალითად, " ახალი კლიენტის " ნაცვლად შესაძლებელია დაწეროთ " %ov%lie% ". გრძელი სახელის შემთხვევაში, ასეთი საძიებო მექანიზმი მნიშვნელოვნად ამცირებს აკრეფის დროს.

საბოლოო ჯამში, როდესაც დაასრულებთ მონაცემთა გაფილტვრის ექსპერიმენტებს, მოდით გავაუქმოთ ფილტრი ფილტრაციის პანელის მარცხენა მხარეს „ჯვარზე“ დაწკაპუნებით.

![]() ახლა მოდით შევხედოთ ფილტრაციას მრავალი პირობით
ახლა მოდით შევხედოთ ფილტრაციას მრავალი პირობით ![]() შეიძლება დაჯგუფდეს .
შეიძლება დაჯგუფდეს .
სხვა სასარგებლო თემებისთვის იხილეთ ქვემოთ:
![]()
უნივერსალური აღრიცხვის სისტემა
2010 - 2024
 ჩამოტვირთეთ პროგრამა ინტერაქტიული ტრენინგით
ჩამოტვირთეთ პროგრამა ინტერაქტიული ტრენინგით