![]() USU
››
ব্যবসা অটোমেশন জন্য প্রোগ্রাম
››
ক্লিনিকের জন্য প্রোগ্রাম
››
মেডিকেল প্রোগ্রামের জন্য নির্দেশাবলী
››
USU
››
ব্যবসা অটোমেশন জন্য প্রোগ্রাম
››
ক্লিনিকের জন্য প্রোগ্রাম
››
মেডিকেল প্রোগ্রামের জন্য নির্দেশাবলী
››
![]() এই বৈশিষ্ট্যগুলি শুধুমাত্র স্ট্যান্ডার্ড এবং পেশাদার প্রোগ্রাম কনফিগারেশনে উপলব্ধ।
এই বৈশিষ্ট্যগুলি শুধুমাত্র স্ট্যান্ডার্ড এবং পেশাদার প্রোগ্রাম কনফিগারেশনে উপলব্ধ।

আমরা যখন লাগাতে শিখেছি ![]() হালকা ফিল্টার , যেখানে আমরা যেকোনো ক্ষেত্রের পছন্দসই মানগুলিতে টিক দিয়ে থাকি। এটি একটি মডিউলের উদাহরণ ব্যবহার করে কঠিন অবস্থার কাজ করার সময় "রোগীদের" একটি জটিল ডেটা ফিল্টারিং সেটআপ কীভাবে কাজ করে তা দেখুন।
হালকা ফিল্টার , যেখানে আমরা যেকোনো ক্ষেত্রের পছন্দসই মানগুলিতে টিক দিয়ে থাকি। এটি একটি মডিউলের উদাহরণ ব্যবহার করে কঠিন অবস্থার কাজ করার সময় "রোগীদের" একটি জটিল ডেটা ফিল্টারিং সেটআপ কীভাবে কাজ করে তা দেখুন।
সঙ্গে ![]() পূর্ববর্তী উদাহরণে, ফিল্টার উইন্ডোতে আমাদের ইতিমধ্যে একটি শর্ত রয়েছে।
পূর্ববর্তী উদাহরণে, ফিল্টার উইন্ডোতে আমাদের ইতিমধ্যে একটি শর্ত রয়েছে।
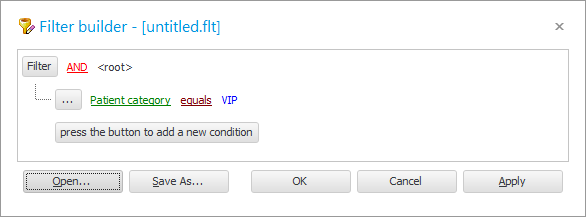
আসুন ' পেশেন্ট ক্যাটাগরি ' ফিল্ডটিকে ' নাম ' ফিল্ড দিয়ে প্রতিস্থাপন করি।
তুলনা চিহ্নকে ' সমান ' থেকে ' সদৃশ ' এ পরিবর্তন করুন।
মান হিসাবে, ' % van % ' লিখুন।
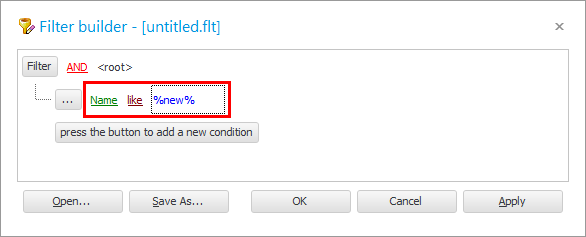
' ওকে ' বোতাম টিপুন এবং ফলাফলটি দেখুন।
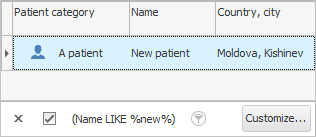
আমরা কি করলাম? আমরা যা লিখেছি তার সাথে ওভারল্যাপ করে এমন এন্ট্রি খুঁজতে শিখেছি। সেজন্য আমাদের তুলনা চিহ্ন প্রয়োজন ' এর মতো দেখাচ্ছে '। এবং ' % ভ্যান% ' শব্দের বাম এবং ডানে শতাংশ চিহ্নের অর্থ হল যে সেগুলি ক্ষেত্রের 'যেকোন পাঠ্য' দ্বারা প্রতিস্থাপিত হতে পারে "রোগীর নাম" .
এই ক্ষেত্রে, আমাদের এমন সমস্ত কর্মচারী দেখানো হয়েছিল যাদের নাম বা পদবি বা পৃষ্ঠপোষকতায় 'আইভান' শব্দটি রয়েছে। এটি হতে পারে 'ইভান্স', এবং 'ইভানভস', এবং 'ইভানিকভস', এবং 'ইভানোভিচি', ইত্যাদি। এই পদ্ধতিটি ব্যবহার করা সুবিধাজনক যখন আপনি জানেন না কিভাবে রোগীর ' পুরো নাম ' ডাটাবেসে লেখা আছে। এবং যখন সমস্ত অনুরূপ রেকর্ড প্রদর্শিত হয়, আপনি সহজেই আপনার চোখ দিয়ে সঠিক ব্যক্তি নির্বাচন করতে পারেন।
শতাংশ চিহ্নটি কেবল অনুসন্ধান বাক্যাংশের শুরুতে এবং শেষে নয়, মাঝখানেও ব্যবহার করা যেতে পারে। তারপর আপনি প্রথম নামের অংশ এবং শেষ নামের অংশ নির্দিষ্ট করতে পারেন। উদাহরণস্বরূপ, ' নতুন ক্লায়েন্ট ' এর পরিবর্তে ' %ov%lie% ' লেখা সম্ভব। একটি দীর্ঘ নামের ক্ষেত্রে, এই ধরনের একটি লুকআপ প্রক্রিয়া টাইপ করার সময়কে ব্যাপকভাবে হ্রাস করে।

শেষ পর্যন্ত, যখন আপনি ডেটা ফিল্টারিং নিয়ে পরীক্ষা-নিরীক্ষা শেষ করেন, ফিল্টারিং প্যানেলের বাম দিকে 'ক্রস'-এ ক্লিক করে ফিল্টারটি বাতিল করি।

![]() এখন এর একাধিক শর্ত দিয়ে ফিল্টারিং তাকান
এখন এর একাধিক শর্ত দিয়ে ফিল্টারিং তাকান ![]() গ্রুপ করা যেতে পারে ।
গ্রুপ করা যেতে পারে ।
অন্যান্য সহায়ক বিষয়গুলির জন্য নীচে দেখুন:
![]()
ইউনিভার্সাল অ্যাকাউন্টিং সিস্টেম
2010 - 2024
 ইন্টারেক্টিভ প্রশিক্ষণ সহ প্রোগ্রামটি ডাউনলোড করুন
ইন্টারেক্টিভ প্রশিক্ষণ সহ প্রোগ্রামটি ডাউনলোড করুন