![]() USU
››
व्यवसाय ऑटोमेशनसाठी कार्यक्रम
››
क्लिनिकसाठी कार्यक्रम
››
वैद्यकीय कार्यक्रमासाठी सूचना
››
USU
››
व्यवसाय ऑटोमेशनसाठी कार्यक्रम
››
क्लिनिकसाठी कार्यक्रम
››
वैद्यकीय कार्यक्रमासाठी सूचना
››
![]() ही वैशिष्ट्ये फक्त मानक आणि व्यावसायिक प्रोग्राम कॉन्फिगरेशनमध्ये उपलब्ध आहेत.
ही वैशिष्ट्ये फक्त मानक आणि व्यावसायिक प्रोग्राम कॉन्फिगरेशनमध्ये उपलब्ध आहेत.

टाकायला शिकलो तेव्हा ![]() लाइट फिल्टर , जिथे आम्ही कोणत्याही फील्डच्या इच्छित मूल्यांवर फक्त टिक करतो. मोड्यूलचे उदाहरण वापरून कठीण परिस्थितीत काम करण्याची वेळ आली आहे "रुग्ण" जटिल डेटा फिल्टरिंग सेटअप कसे कार्य करते ते पहा.
लाइट फिल्टर , जिथे आम्ही कोणत्याही फील्डच्या इच्छित मूल्यांवर फक्त टिक करतो. मोड्यूलचे उदाहरण वापरून कठीण परिस्थितीत काम करण्याची वेळ आली आहे "रुग्ण" जटिल डेटा फिल्टरिंग सेटअप कसे कार्य करते ते पहा.
सह ![]() मागील उदाहरणात, आमच्याकडे फिल्टर विंडोमध्ये आधीपासूनच एक अट आहे.
मागील उदाहरणात, आमच्याकडे फिल्टर विंडोमध्ये आधीपासूनच एक अट आहे.
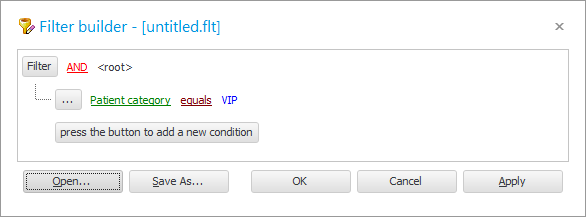
चला ' रुग्ण श्रेणी ' फील्ड ' नाव ' फील्डने बदलू.
तुलना चिन्ह ' समान ' वरून ' समान ' वर बदला.
मूल्य म्हणून, ' %van% ' प्रविष्ट करा.
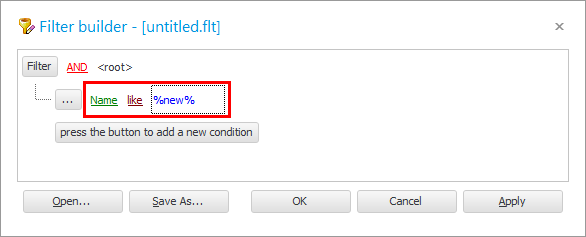
' ओके ' बटण दाबा आणि निकाल पहा.
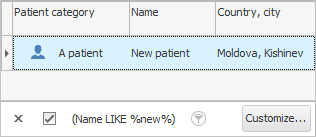
आम्ही काय केले आहे? आम्ही लिहिलेल्या नोंदींशी ओव्हरलॅप करणार्या नोंदी शोधायला शिकलो आहोत. म्हणूनच आम्हाला तुलना चिन्ह ' सारखे दिसते ' आवश्यक आहे. आणि ' %van% ' शब्दाच्या डावीकडे आणि उजवीकडील टक्के चिन्हांचा अर्थ असा होतो की ते फील्डमधील 'कोणत्याही मजकुराने' बदलले जाऊ शकतात. "रुग्णाचे नाव" .
या प्रकरणात, आम्हाला असे सर्व कर्मचारी दाखवले गेले ज्यांच्या नावात किंवा आडनावात 'इवान' हा शब्द आहे. हे 'इव्हान्स', आणि 'इव्हानोव्ह्स', आणि 'इव्हानिकोव्ह्स' आणि 'इव्हानोविची' इत्यादी असू शकतात. डेटाबेसमध्ये रुग्णाचे ' पूर्ण नाव ' नेमके कसे लिहिले जाते हे आपल्याला माहिती नसताना ही यंत्रणा वापरण्यास सोयीस्कर आहे. आणि जेव्हा सर्व समान रेकॉर्ड प्रदर्शित केले जातात, तेव्हा आपण सहजपणे आपल्या डोळ्यांनी योग्य व्यक्ती निवडू शकता.
टक्के चिन्ह केवळ शोध वाक्यांशाच्या सुरूवातीस आणि शेवटीच नव्हे तर मध्यभागी देखील वापरले जाऊ शकते. नंतर तुम्ही नावाचा काही भाग आणि आडनावाचा भाग निर्दिष्ट करू शकता. उदाहरणार्थ, ' नवीन क्लायंट ' ऐवजी ' %ov%lie% ' लिहिणे शक्य आहे. लांब नावाच्या बाबतीत, अशी लुकअप यंत्रणा टायपिंगचा वेळ खूप कमी करते.

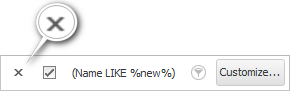
शेवटी, तुम्ही डेटा फिल्टरिंगचा प्रयोग पूर्ण केल्यावर, फिल्टरिंग पॅनेलच्या डाव्या बाजूला असलेल्या 'क्रॉस' वर क्लिक करून फिल्टर रद्द करूया.

![]() आता अनेक अटींसह फिल्टरिंग पाहू
आता अनेक अटींसह फिल्टरिंग पाहू ![]() गटबद्ध केले जाऊ शकते .
गटबद्ध केले जाऊ शकते .
इतर उपयुक्त विषयांसाठी खाली पहा:
![]()
युनिव्हर्सल अकाउंटिंग सिस्टम
2010 - 2024
 संवादात्मक प्रशिक्षणासह प्रोग्राम डाउनलोड करा
संवादात्मक प्रशिक्षणासह प्रोग्राम डाउनलोड करा